
Using AI for Personal Data
Actually using the data that is collected on us and around us

These days, there’s data everywhere. There’s data on the economy, on education, demographics, energy, housing, crime; the list goes on and on. There’s also data collected on you and I. In the course of using digital services, we generate a staggering amount of information: browsing history, location data, financial transactions, biometrics, communications, our media consumption; the list goes on and on.
Being able to use data effectively is enormously valuable. It helps you cut through your biased or flawed intuitions, and understand things in systematic ways that can be reviewed by others. Increasingly, we need data to understand the world we live in and to make decisions on how we navigate it personally. It helps us understand our businesses, our politics, and our own lives. Big companies know this, great journalism knows this, most genuinely curious people know this.
The catch is that proper data science is neither easy nor simple. It takes time and expertise to gather data, to organize it, and then to store it in a way that is easy to work with. Once you do that, it takes time and expertise to develop a sense for how to ask questions, how to formulate those questions into procedures, and finally to understand the nuances of the procedures given the semantics of the prepared data. Then, if you want to share those results or understand them deeper, you need the communication skills to know how to best articulate the results via charts and prose.
If people are not using data in their daily lives it’s not because there’s a lack of data or because we’re not convinced doing so is useful—it’s because it takes too much skill, effort, and time. Some nerds like Simon Willison, Stephen Wolfram, Andrej Karpathy have been ahead of the curve, but for the rest of us, we get the basic charts that services like Apple Health or Google give us, and have no real ability to dive in to our personal data.
I have been doing small scale data work with AI over the last few months on my Zo Computer and it feels like a glimpse of the future. In this post I want to share a bit around the things I’ve been doing, how I think about it, and some features we’ve built into Zo as a result of my own explorations.
Personal Data
Thanks to legislation like GDPR, nearly all services we use provide a way to download all of your data via some kind of data export tool. Google has an entire product for helping you do this called Google Takeout. For things like Instagram, X, Amazon, Spotify, LinkedIn, etc it will usually involve requesting a data export and getting a giant .zip file emailed to you a few days later. It’s always been a kind of silly bit of compliance because these data dumps are typically totally without documentation and can be up to terabytes of data. Companies hand them off to you and say “good luck”.

The thing is with AI, these data dumps are becoming much more useful to regular consumers. Agentic systems in particular can extract it, inspect it, run code to import it all into a legible format, and then do analysis on it. It takes some work, but is dramatically more accessible than before, where you practically had to be a trained data scientist with a lot of spare time to do anything meaningful.
Organizing Data
For me the goal with a lot of these personal data explorations was to get my data into a database with good documentation that I could then feed into an LLM to help me query against. Essentially it was to make mini-ETL pipelines that involved having an LLM sample a lot of raw data to get a sense for what was there, write an ingestion script for how to go from messy source files into a single DuckDB, then have the LLM write out schema information and document business rules around the data in Markdown. Once you have all of this, you can start to have an LLM explore those questions agentically.
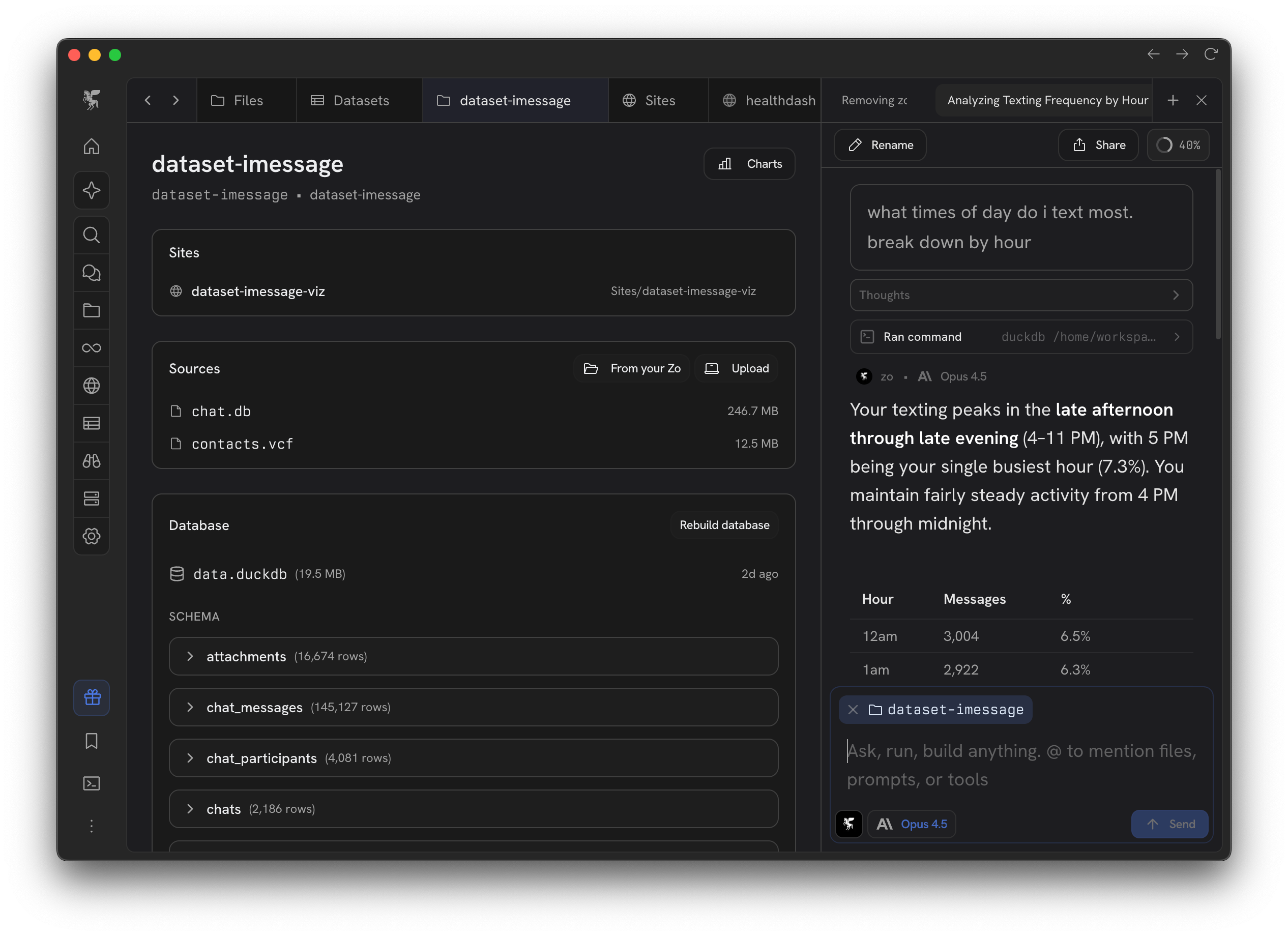
Charting and Interpretation
Having the data documented in a nice DuckDB is great for general purpose use, but when it comes time to understanding, I usually want a more interactive form that is some mixture between graphics, tables, and text. I do this in Zo, where the agent already has a well-documented way to make charts and web pages so it can pretty much always one-shot something that looks great and works. When you make these interactive charts and analyses on Zo, they are private by default, but can be published publicly as a site with a click.
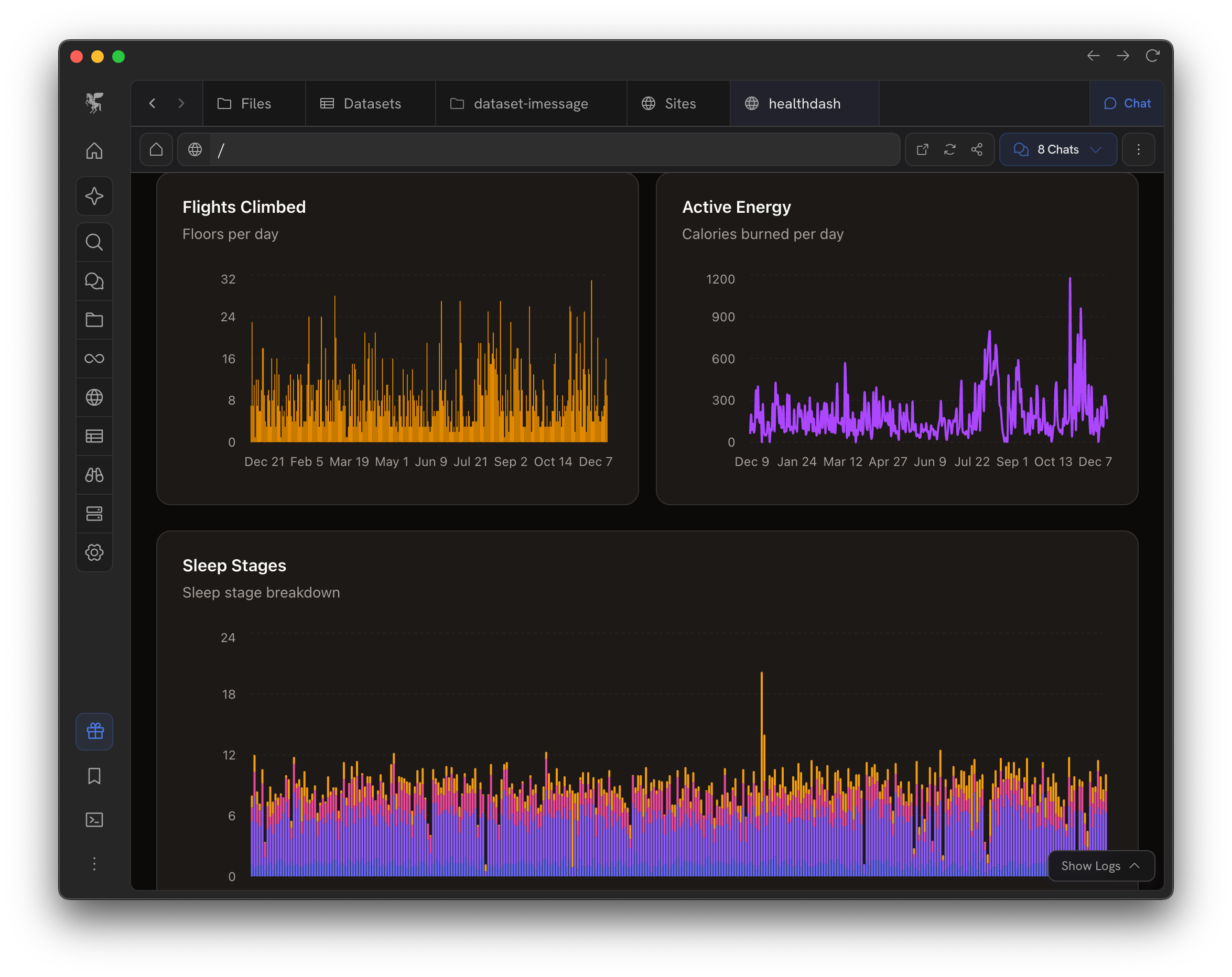
Examples
In the beginning, I started making data projects just for things I was curious about. People were talking quite a bit about food stamps during the government shutdown and I pulled data to understand just how broadly it was used and by whom. Similarly with interest rate data, understanding how the Fed has performed on it’s dual mandate of managing unemployment and inflation via rates. It’s so nice to have dynamic interactive models to play with when trying to understand things like this. It’s like having an interactive malleable blog post where every time I have a new question or want to dive a click deeper, I can get a new version of a rich document.
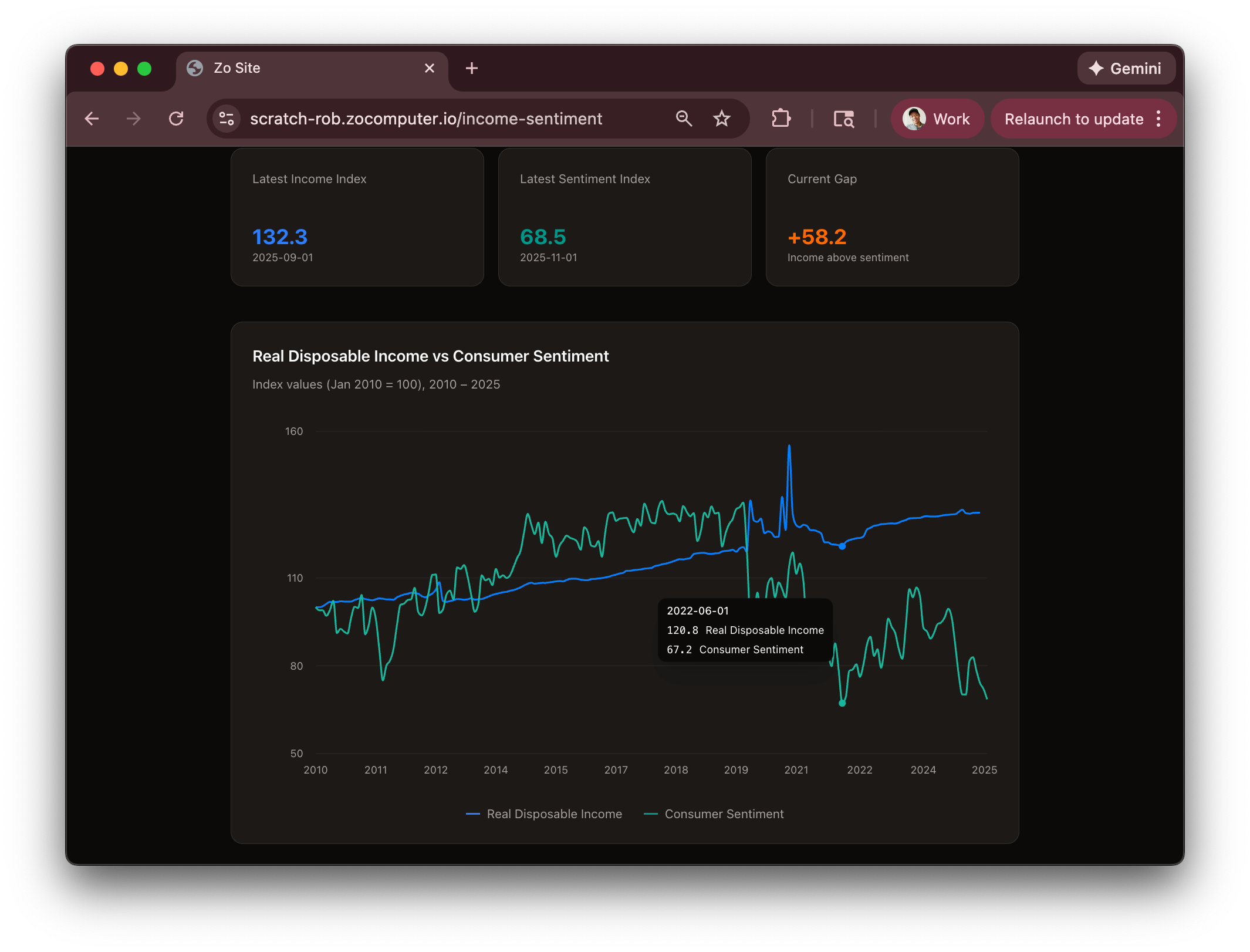
After using it to explore general curiosities, I had a period where I started importing a lot of personal datasets. I imported all of my Apple Health data going back years, my genome data, my credit card data, my entire X/Twitter dump, letterboxd, iMessage history, Spotify export, Amazon history, Google data, Claude history, and even Doordash history. My Zo is my personal server so all the data is totally private to me until I send off slices to an LLM for analysis.
This process has been both very fun and enlightening. I know now for example that not only are my Vitamin D levels critically low this winter due to lack of sunlight, but also because it found two genes (DHCR7, CYP2R1) that indicate that I am genetically ineffective at generating and absorbing it, which led to my supplementing more. Finding recurring subscriptions on my credit card is super easy and it led to my cancelling some unused ones. With your messaging data you can rediscover some great moments, understand your communication style more objectively (what is your actual median response time?), and even run some fun personality assessments on yourself and friends. What’s cool when you have all of this data in one place, is that you can cross-query. Sure, Spotify Wrapped can tell you statistics on your listening, but when you have all the data yourself you can ask questions like “what do I listen to when I work out?” which resolves to intersecting your listening data with your workout data.
The Future
Increasingly, I am gathering more data on myself only for myself. Before he was as well known, Andrej Karpathy published a little repo called ulogme 11 years ago that had a local process track nearly everything he did on his computer, like how much time he spends in apps, on different websites, when he types on his keyboard, etc. It’s an enormous amount of sensitive data, and really something you would only want stored and analyzed locally for yourself. A lot of the data I currently have on myself is mediated through services I use, but I suspect we will increasingly custody more truly personal datasets like this in the future (e.g. I’ve rewritten ulogme recently and am planning on making myself a personal iOS app which just streams iPhone data back to my own DBs) which we’ll all analyze privately for our own uses on our own computers.
To date, access to this stuff has been limited to technical nerds, and even then, only the ones with free time and motivation. But with agentic AI systems, doing stuff like this is getting dramatically more accessible by the day. I can now spin up massive databases on my Zo in seconds, start asking questions, take notes, and build reports with way less effort than I previously imagined possible. Knowing that I can ground thinking in data more easily not only changes how I go about exploring ideas, but it actually changes how I think.
No matter where you exist on the political spectrum, polling indicates all time lows in institutional trust. Increasingly we are unable to make sense of economic, political, and demographic realities because we both cannot trust institutional narratives and are cognitively overloaded with information. I am not purporting that personal data science will fix what are deep social issues, but I am also hopeful that this kind of capability broadly orients us more in the right direction. If on the margin we drive our discourse and our sense-making on more empirical grounds, then we can at least debate on more solid foundations. Yes, data can be spun, but at least we are communicating around specific measures, methodologies, and procedures. In an increasingly complex world, it is all too easy to develop distorted intuitions. And while we shouldn’t abandon our felt experiences, we do need to augment them with more holistic information analyzed as dispassionately as we can muster.
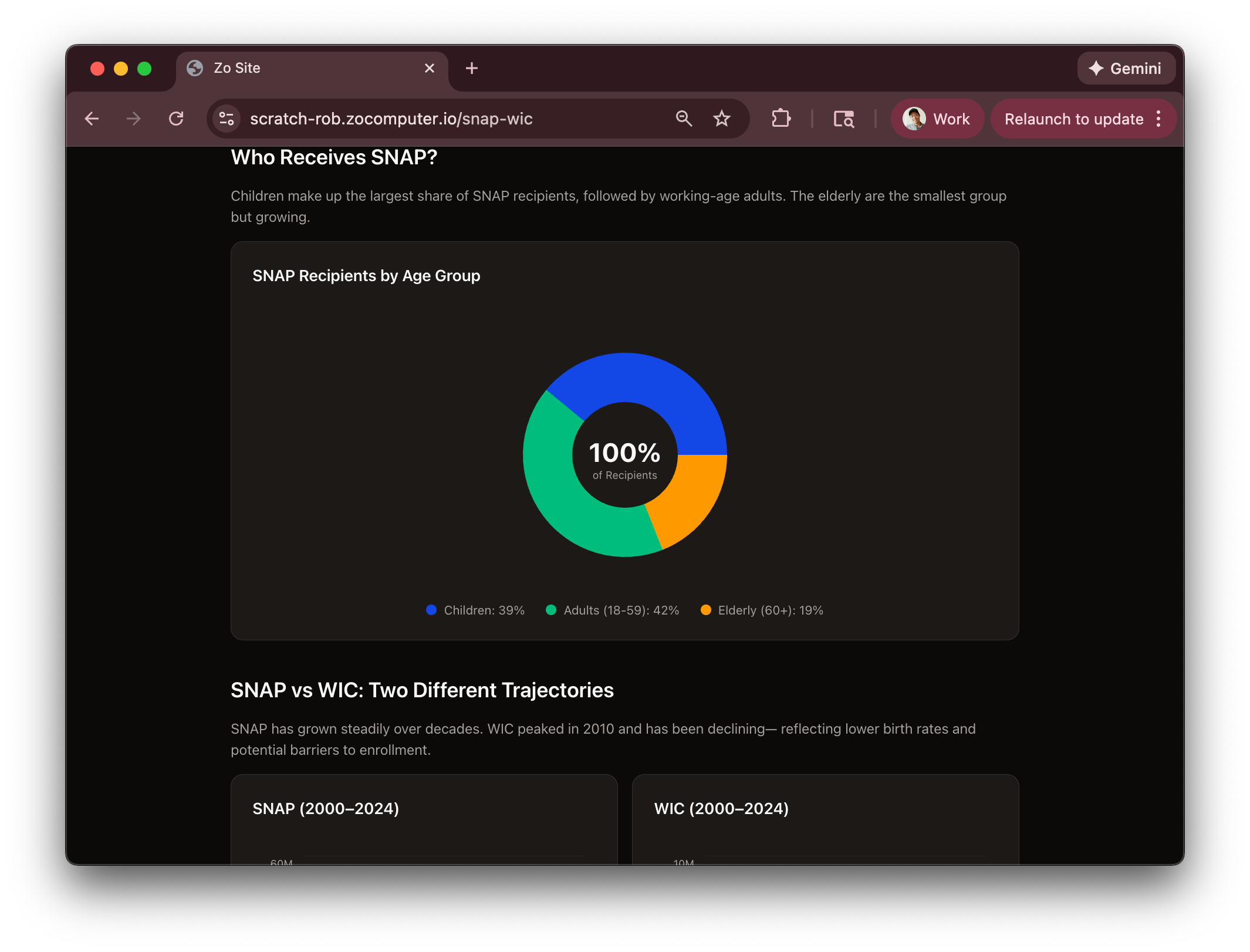
Zo Datasets
As a result of all of this manual data exploration, we’ve built in some features into Zo Computer, a startup I’m working on that gives you your own intelligent cloud computer where you can house all your files and work with them using agentic AI.
Zo Datasets is basically a mini-ETL pipeline that can take in datasets in any form. You can import data from platforms like Instagram, Spotify, Amazon, etc. or bring your own (or have Zo gather it from the web for you) datasets like demographic data, energy data, etc. Zo will automatically inspect it, decide how to organize and load it into a nice clean database, document that database, then let you ask questions or build artifacts from it. It’s designed to be a general framework that accepts any data, and it will apply a basic set of operations that resemble what a professional Data Scientist would do to prepare messy information for analysis.
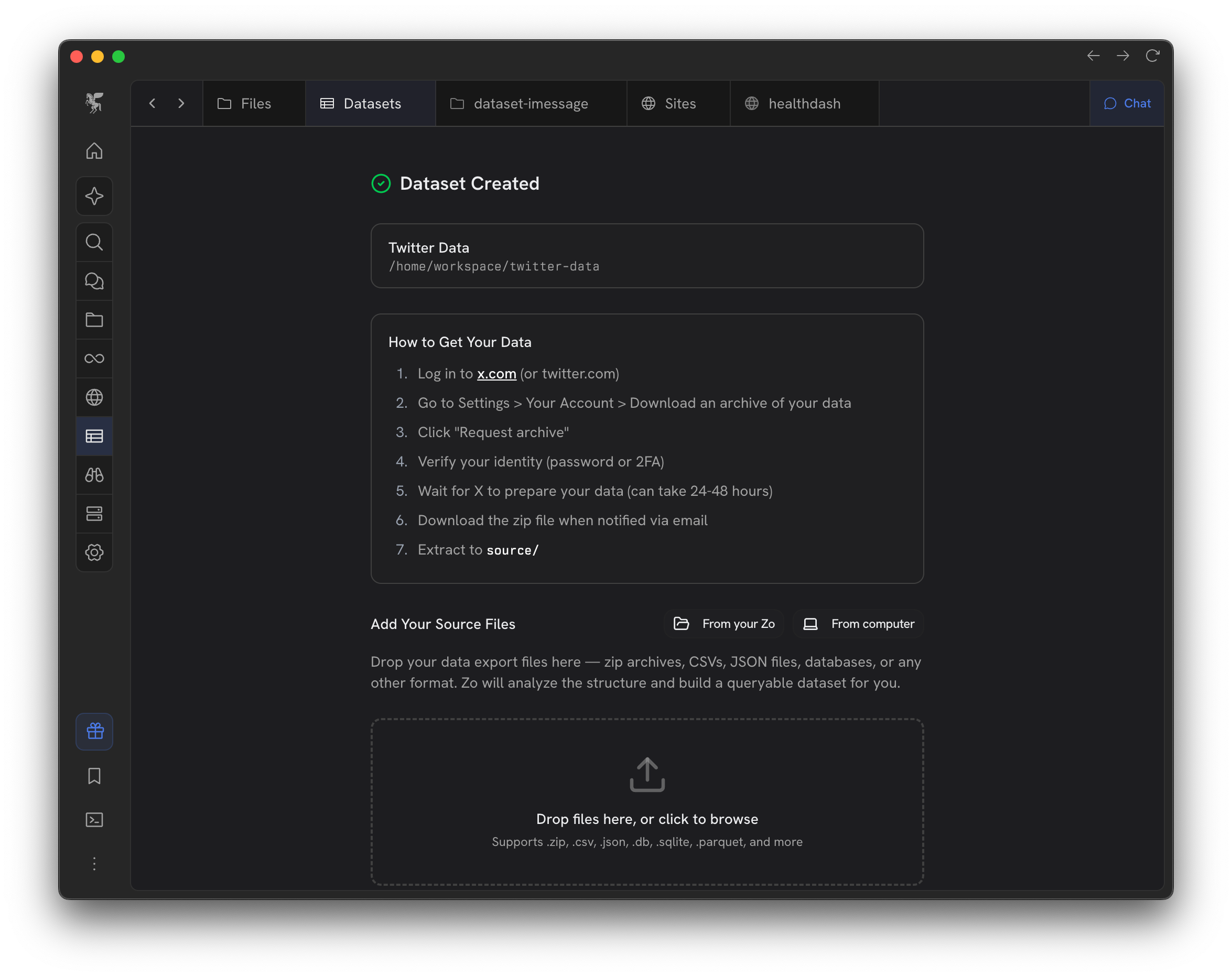
We have built in templates for some common data exports, but you can always start fresh, drag files into a dataset’s “source” folder, and tell Zo to prepare it for analysis. As a fun bonus we’ve even included an automatic pipeline to “2025 Wrapped” anything, whether it’s your Netflix data, Amazon history, or even Doordash (lol) data.
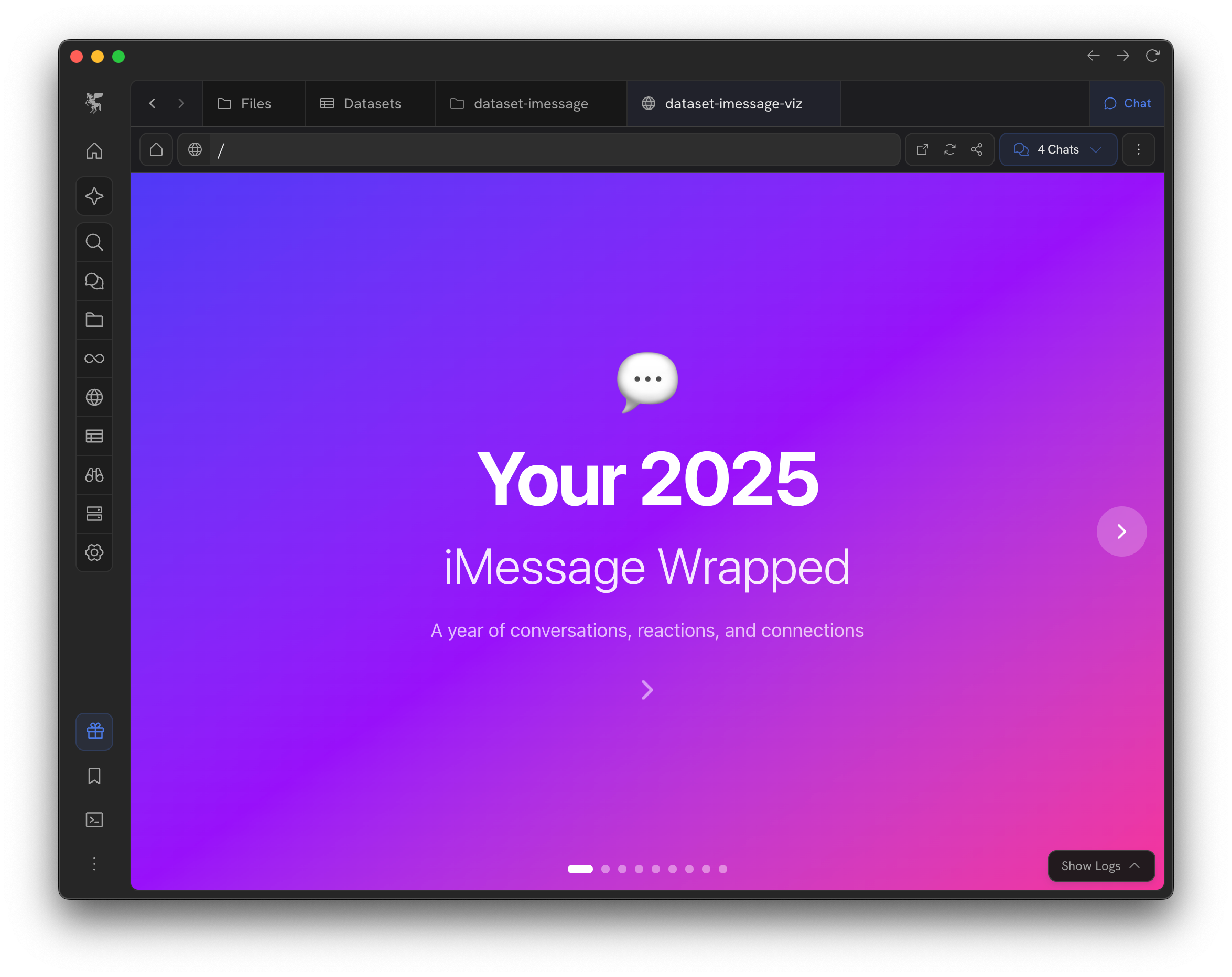
It’s still in it’s infancy, but we think Zo Datasets represents a broader improvement for each of us to work with the enormous amounts of structured data collected around us, and on us. The beginning of knowledge should be evidence and access to that evidence should improve with technology. As a nerd, this project and what it represents is very near to my heart; I believe that even slightly more data literacy across our society can help massively with discourse, progress, and ultimately collective wisdom.
This is incredible, Great way to attack a specific bottleneck
Love the data set tool so much!!!